Premiers travaux sur Uwazi
-
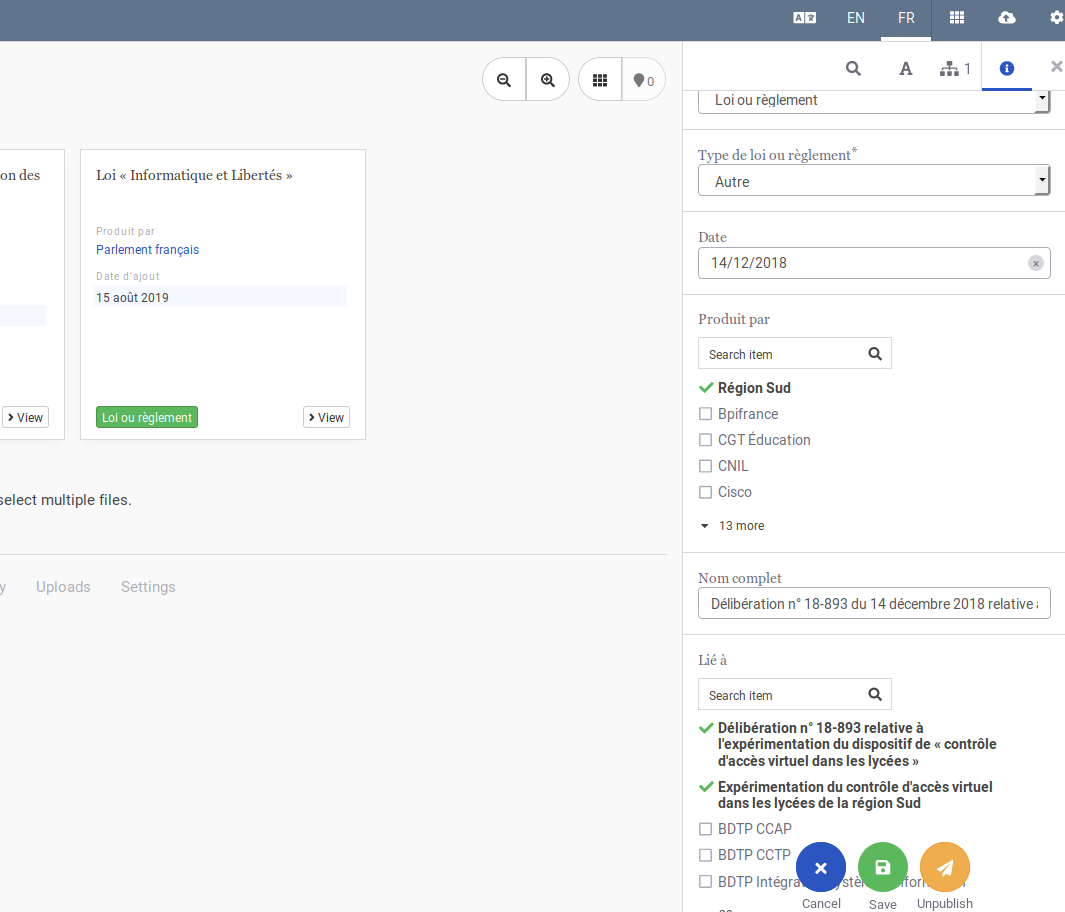
J'ai pris un peu de temps pour définir des taxonomies dans Uwazi, l'outil qui nous permettra d'agréger toutes sortes de documents en lien avec la campagne (lois, documents administratifs, mémoires, jurisprudence, écrits militants, notice technique ou brevets, etc.). Il y a quelques petits bugs (faudra voir à bien faire les mise-à-jour) et quelques petites fonctionnalités qui font un peu défaut (ça viendra sans doute) mais globalement ça marche très bien. Et c'est parfait pour notre usage, à savoir répertorier en les organisant des documents liés à la safe city.
Définir l'architecture de la base Uwazi
Du coup, j'ai défini plusieurs type d'entités (toutes des documents, sauf pour les acteurs et les projets) :
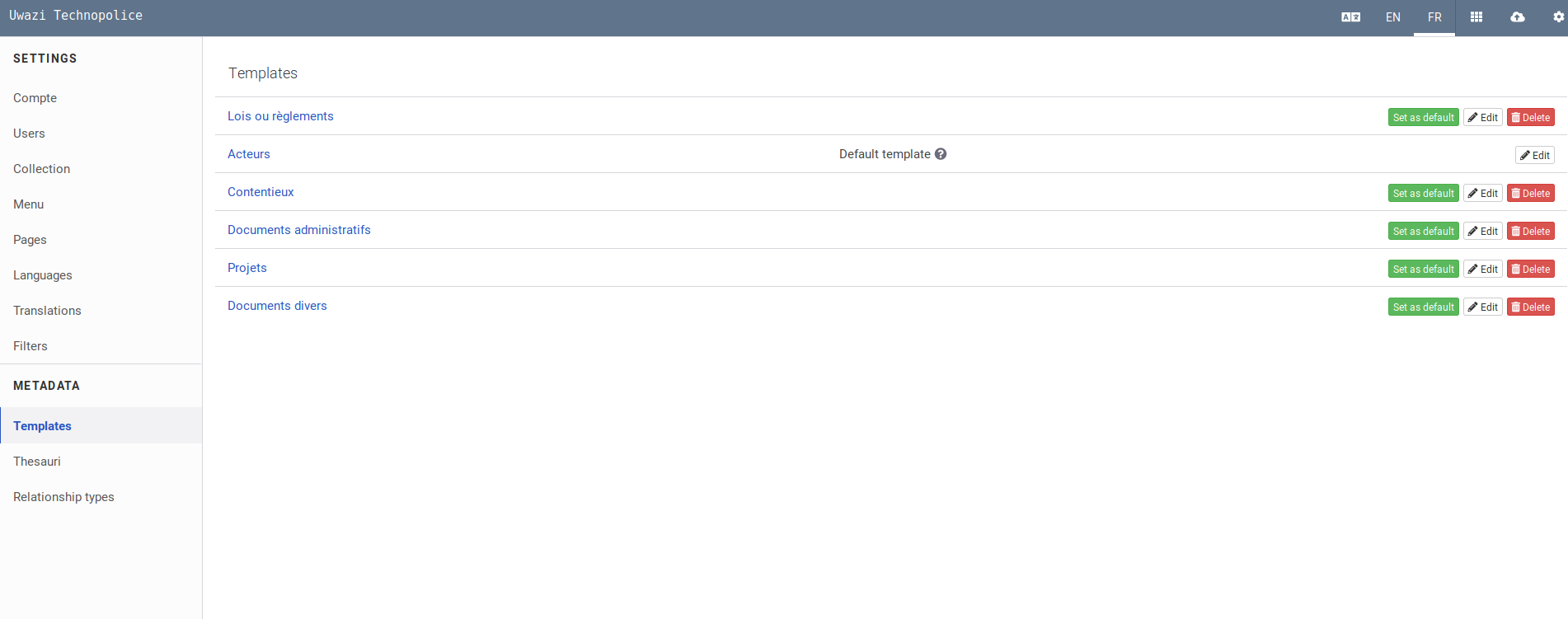
Par exemple pour les entités "Documents administratifs", la taxonomie a été définie comme suit (on choisit le type de champ, l'intitulé, le cas échéant le type de "listes de mots", elles-mêmes définies dans le Thesauri) :
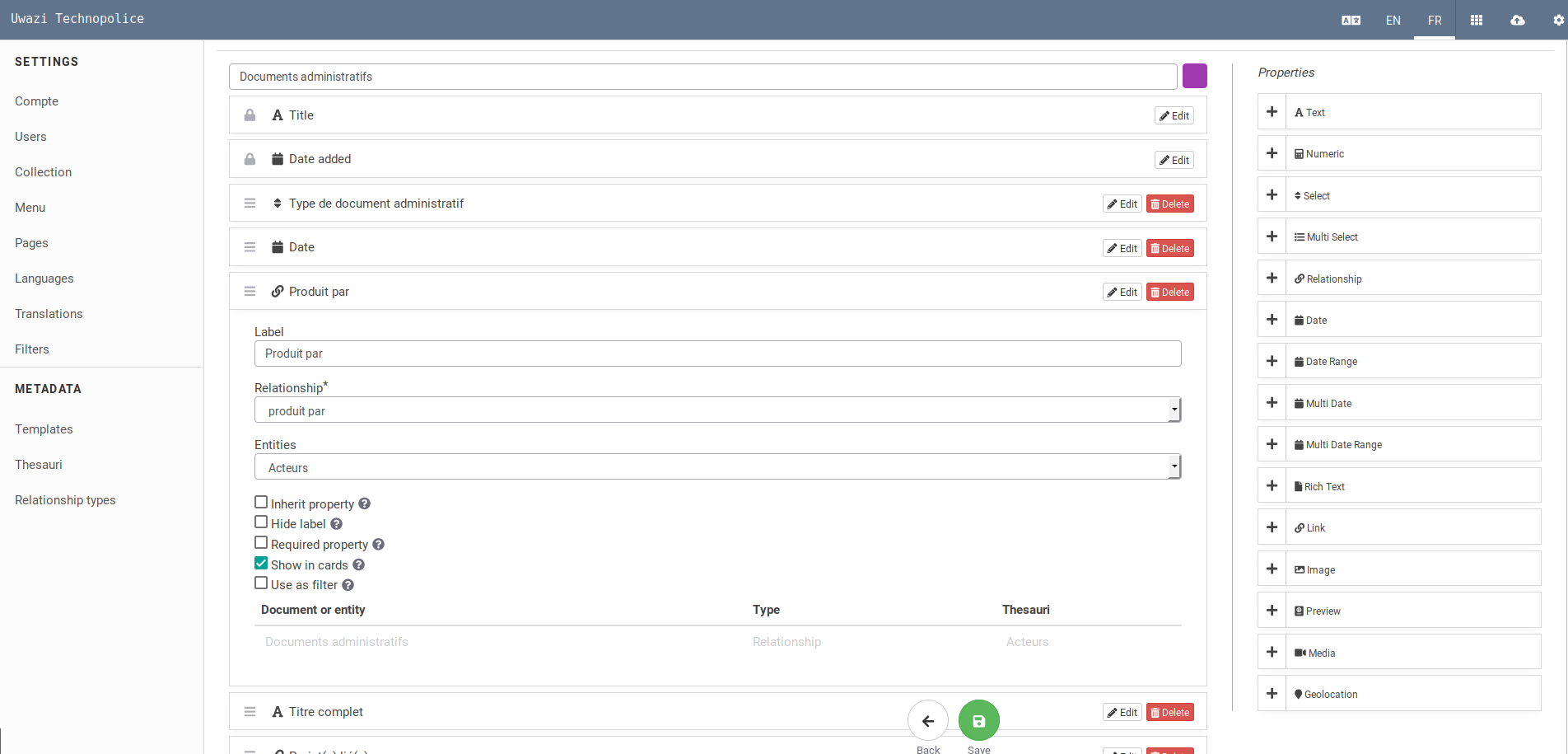
Certains de ces champ(s) sont des "relations" ou "connexions" qu'on peut définir dans l'onglet dédié :
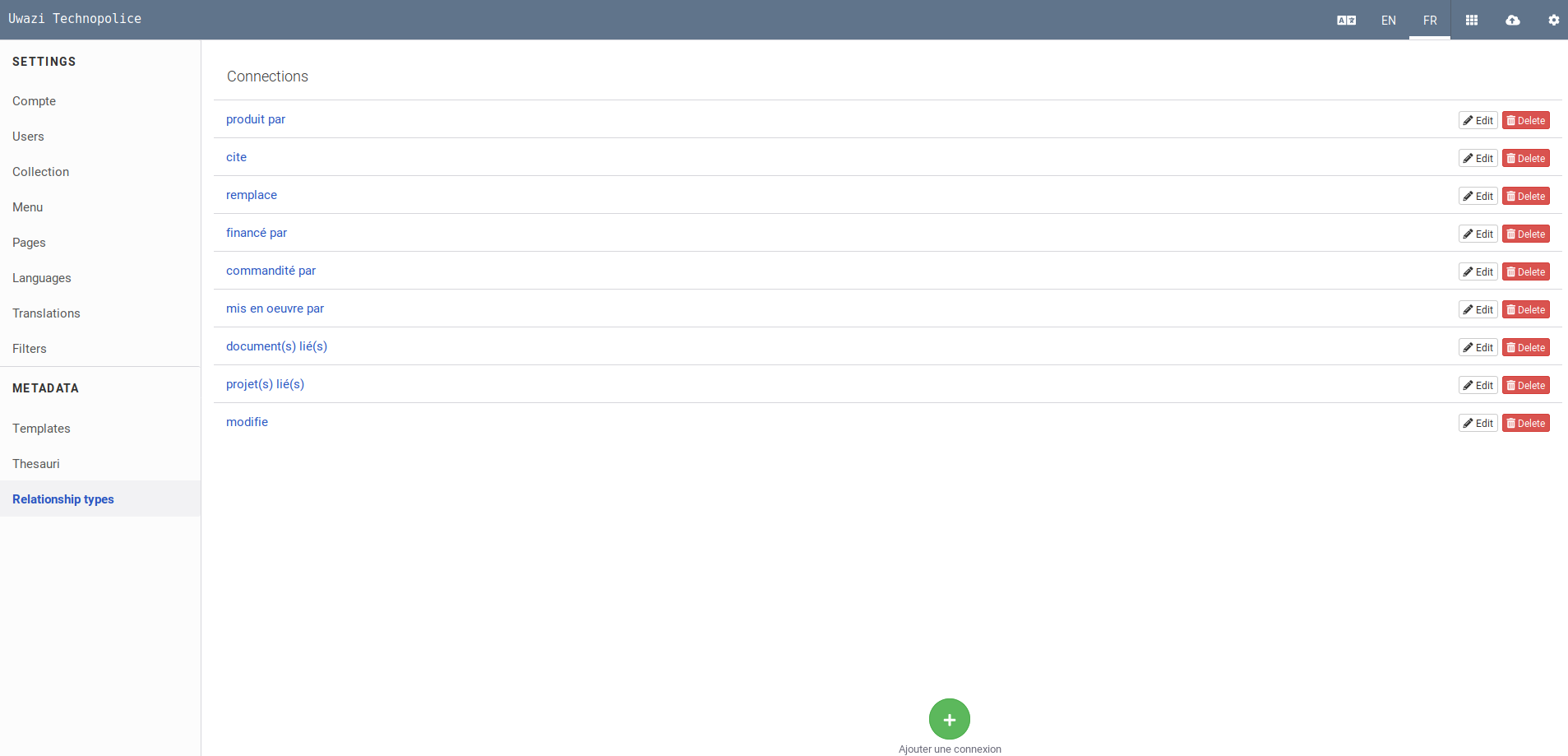
Importer des PDF, créer des entités
Une fois qu'on a mis au point la méta-structure (qui est facile à faire évoluer au début d'un projet, mais plus après car on risque de perdre les contenus déjà renseignés dans les champs), on peut passer à l'importation de documents. Pour ce faire, il faut cliquer sur l'icône du nuage en haut à droite. On importe le PDF (ou des CSV/ZIP), puis on se met à remplir les champs... (on s'est assuré au préalable d'avoir créé les entités des acteurs correspondant pour pouvoir pointer vers le(s) auteur(s) du doc en question) :

Et au bout du compte, à travers les champs de type "relation" ("Produit par", "Document(s) lié(s), etc.), on construit des relations entre tous cas objets.
Publication, visualisations
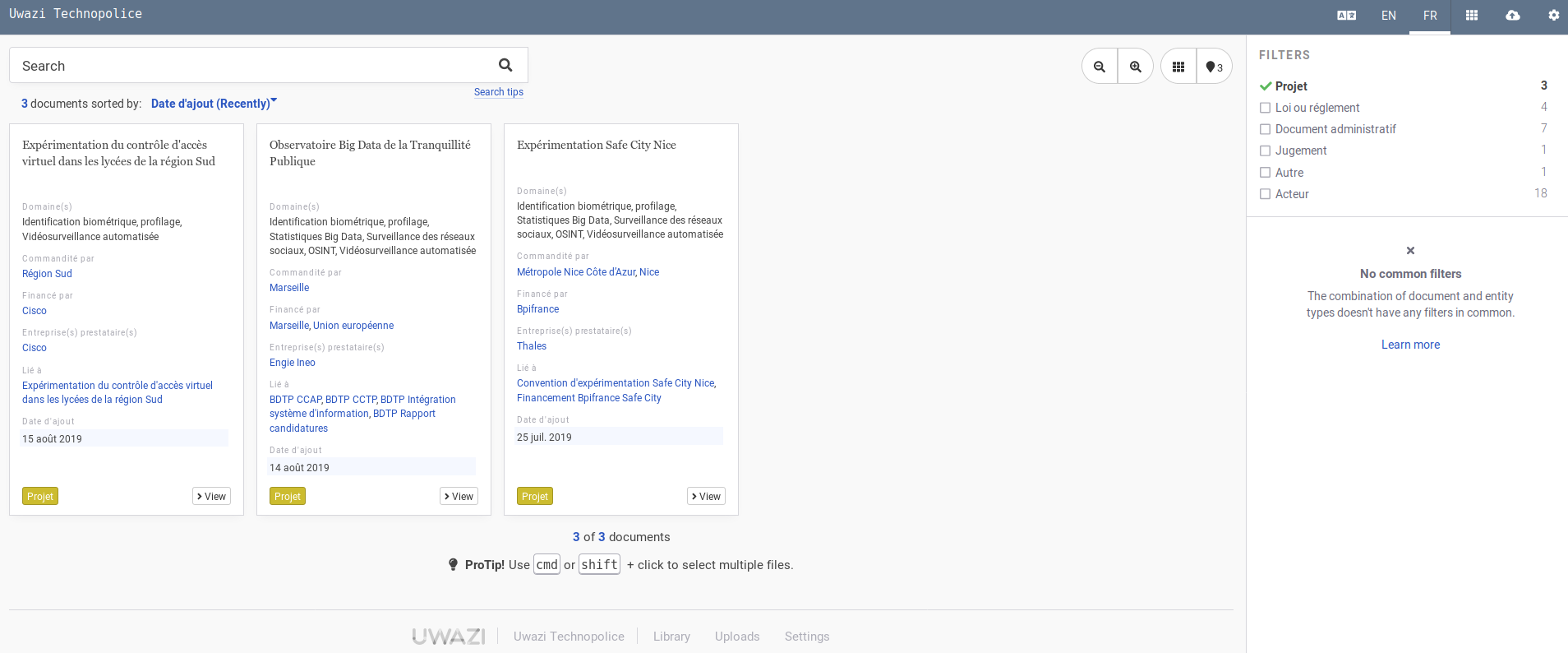
Une fois qu'on a importé des documents, on peut passer ces « documents privés » dans la partie publique du site (en cloquant l'icône "publier"). Ici, en mode public, différents filtres permettent de faire des recherches assez poussées du type de documents/entités désirés (ici, les projets) pour ensuite faire de la recherche dans les textes (lorsque les PDF ont été OCRisés...) :
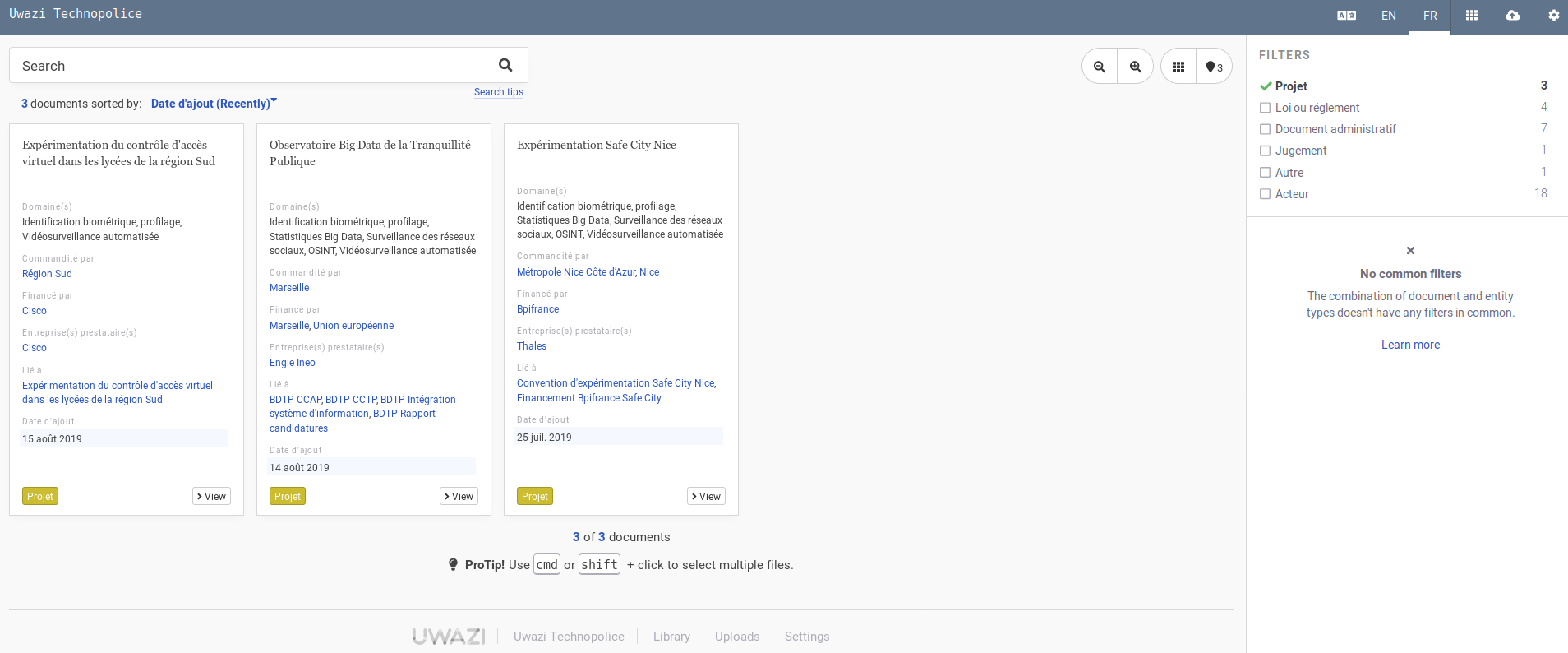
D'autre visualisations intéressantes sont disponibles. Par exemple la notice d'une entité.
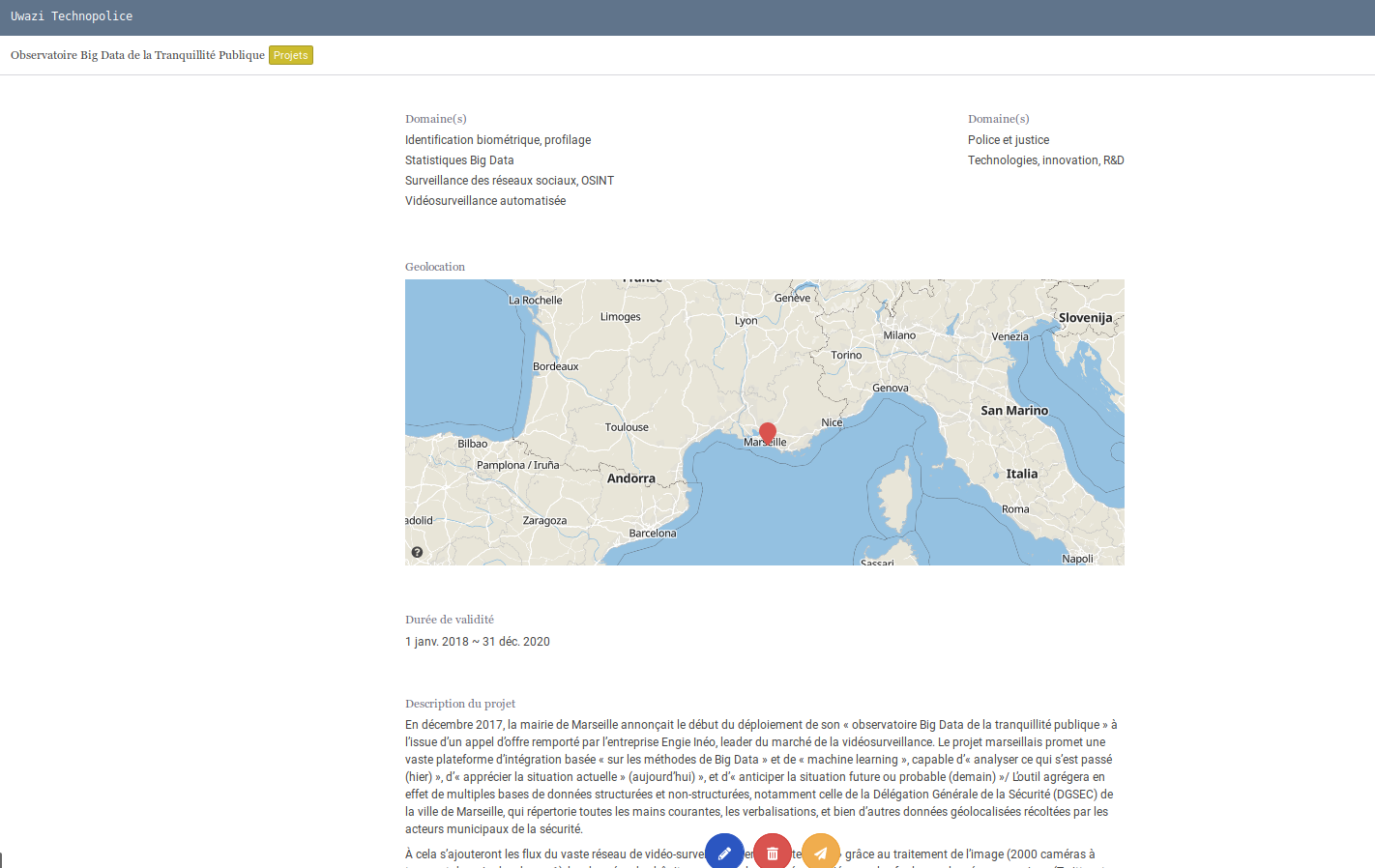
Ou la cartographie des entités sélectionnées (permettra d'avoir facilement une carte des projets) :
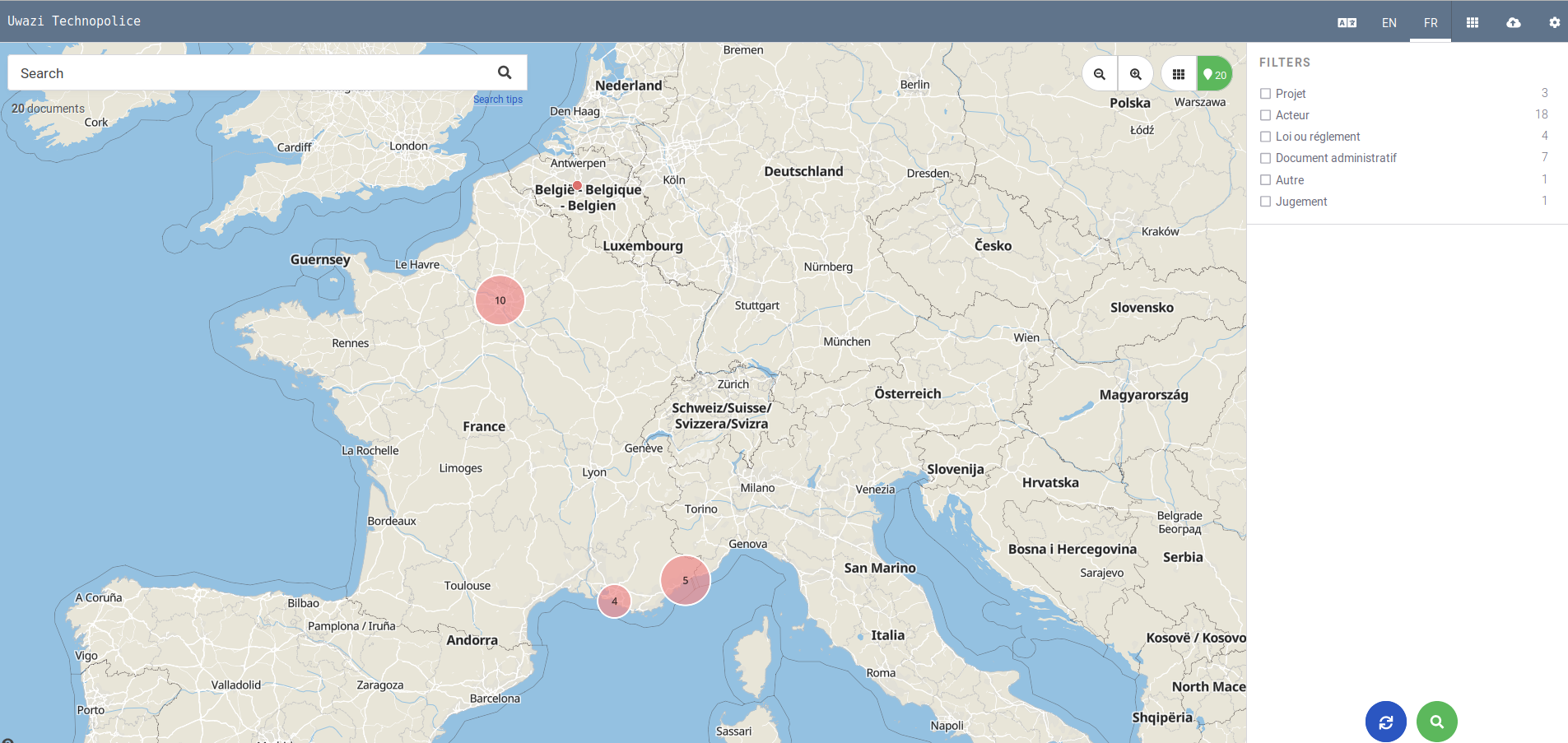
Une fois qu'on a créé ces relations, soit au gré de la lecture du doc soit en remplissant sa notice (avec les champs "Produit par", "Projet(s) lié(s)", "Document(s) lié(s) ou via des références intertextuelles), ça donne ceci :
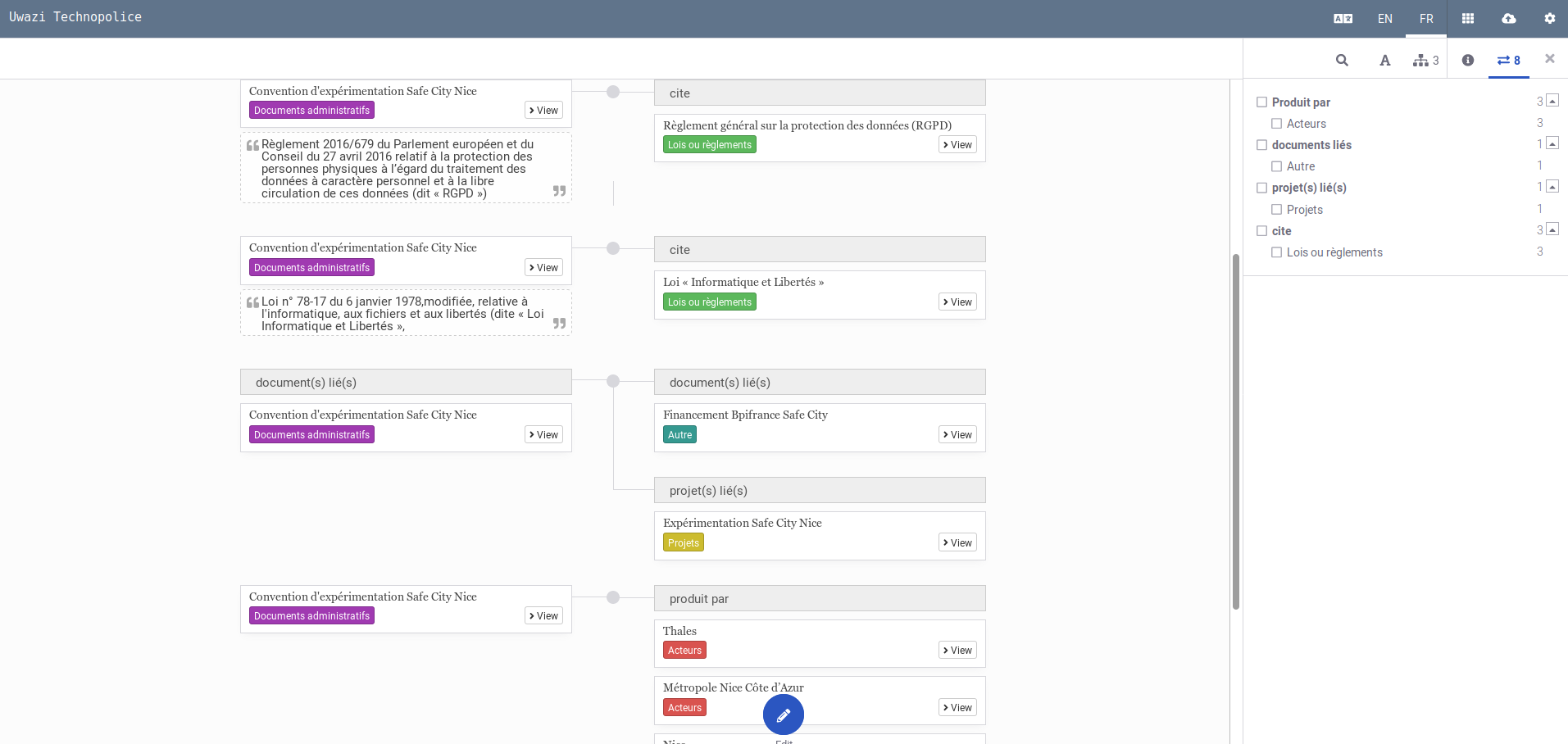
Créer des références intertextuelles entre documents
On peut cliquer sur l'onglet "View" (tout ça sera à traduire) pour lire le PDF et créer des correspondances avec d'autres documents ou entités qui seraient cités (il suffit de sélectionner le passage du texte en question, de choisir le type de relation -- "cite" ou "document(s) lié(s)" quand le lien est plus direct). On peut faire ces références vers des documents entiers ou des paragraphes spécifiques en leur sein.

Bugs...
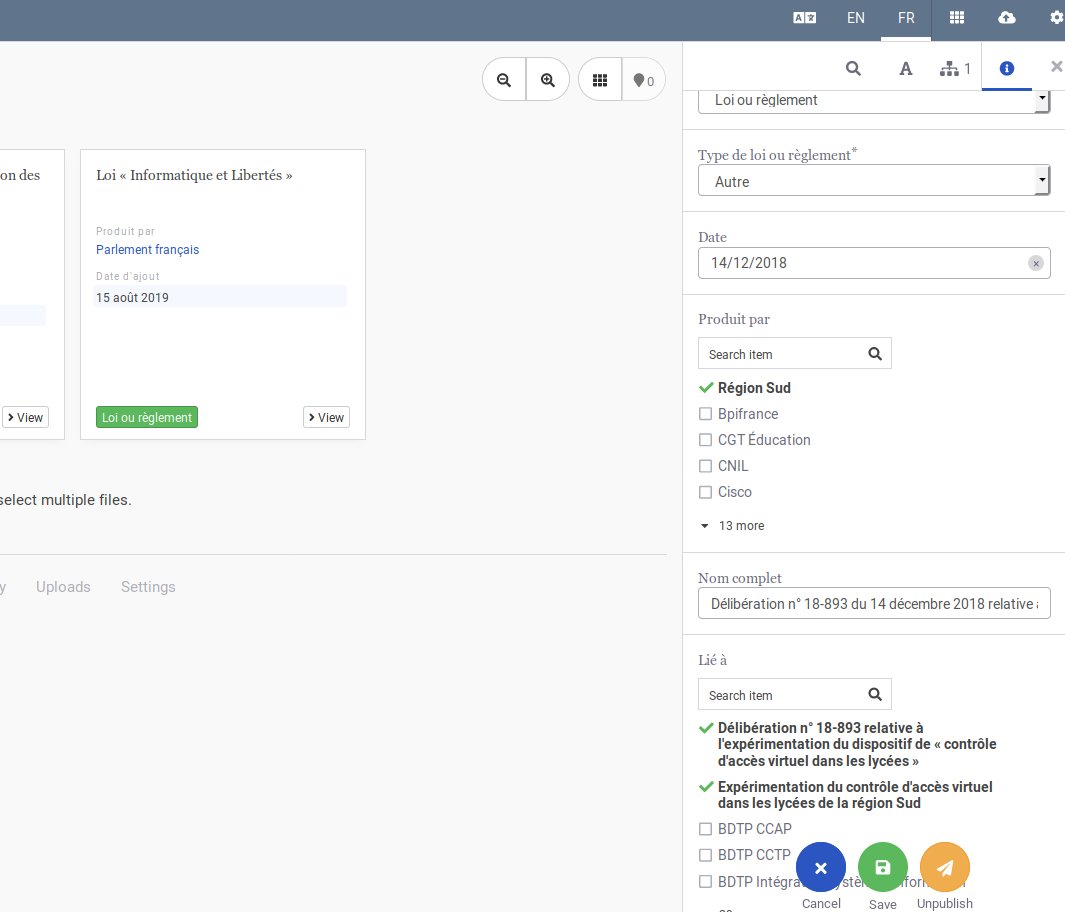
Parfois il y a des choses redondantes, j'ignore pourquoi, mais sous cette vue c'est assez simple de corriger des choses en double ou pas cohérentes. Autre bug un peu ennuyeux, c'est qu'une fois que je modifie la taxonomie (renomme des champs, en supprime, etc.) il n'apparaissent pas tout de suite dans les entités affectées. Un exemple avec les entités "Documents administratifs" où le champ "Type de document administratif" ne me donne pas la liste de mots définis (même problème avec les "Type de loi ou règlement") et le champ "Lié à" devrait normalement s'appeler "Document(s) lié(s)". Problème de cache ?
Autre truc qui ne va pas : les URL. J'ai un message d'erreur chaque fois que j'en renseigne une dans les champs dédiés.
ValidationError: child "metadata" fails because [child "url" fails because ["url" must be a number, "url" must be a string, "label" is not allowed, "url" is not allowed, "url" must be an array, child "label" fails because ["label" is not allowed to be empty], "url" must be an array, "url" must be an array]]
Rien de trop bloquant pour le moment, mais si quelqu'un sait de quoi il s'agit...
D'autres pour jouer ?
En tous cas si @Gof ou @Martin veulent faire un essai d'importer des documents qu'on aurait sous la main et OCRisé, ça m'intéresse car vos retours nous permettront de voir si la taxonomie est bien construite, si des choses manquent ou peuvent être rendues plus claires...
-
Merci pour tout ce boulot ! Pas encore je crois de doc OCRisé mais je regarde !
-
Merci pour tout ce travail, c'est très intéressant. Afin de pouvoir réaliser un travail statistique ensuite sur les acteurs, est-il possible d'ajouter des éléments sur les acteurs privés impliqués (sociétés, bureaux d'études), les personnes référentes dans chaque ville, les maires concernés avec leur appartenance politique, les personnes consultées dans le processus. Qu'en pensez-vous ? Cela permettra de voir les réseaux en jeu sur l'ensemble du pays.
-
Bonjour Thomas. Uwazi sert avant tout de base de données pour analyser des documents. Pour l'analyse des réseaux d'acteurs, nous avons avancé sur cet outil de graphe auquel nous pouvons te donner les droits d'accès pour que tu ajoutes ces infos.
-
@felix Merci ! Quel beau travail !
-
Ok ! J'ai fait un essai sur le bilan annuel des drones d'Istres, et ça m'a parut assez compréhensible une fois qu'on s'y plonge. Mais j'ai peut être fait n'importe quoi.
Ca mérite peut être en effet un mini guide d'utilisation. Mais ca reste un super outil quand même !
-
Super tu t'en es sorti comme un chef;). Il faudra qu'on discute de la taxonomie des applications Safe City utilisées pour catégoriser les entités...